Imagine walking into a familiar restaurant. Instead of the typical one-size-fits-all menu, the waiter greets you by name, knows you’re vegan, and hands you a menu tailored to your taste. No irrelevant dishes. Only what you’d actually consider ordering.
That’s what Context-Aware Retrieval-Augmented Generation— or CAG— aims to achieve for your Java-powered AI applications. Instead of serving the same bland information dish to everyone, you personalize every reply by “grounding” retrievals with real-world contexts: user role, location, time, maybe even intention.
In this article, you’ll see how context-driven RAGs make business logic sharper and user experiences richer. We’ll share approaches, discuss best practices, walk through hands-on Java code, and demonstrate how to plug smart retrievals into your LLM pipeline. And, of course, we’ll show why the approach behind byrodrigo.dev leaves competitors a few steps behind— in robustness, performance, and flexibility.
What is CAG and why should developers care?
CAG, or more formally “Context-Aware Grounded RAG,” is a twist on standard retrieval-augmented generation: you supply metadata, like user profile or moment-in-time, and the system shapes retrievals (and responses) accordingly. Instead of that one bland menu, you get one for each guest.
Better answers start with better context.
Where vanilla RAG feeds user queries straight to a vector search (“Find the chunks closest to this embedding”), context-aware retrieval adds layers: “Find the chunks most relevant to this embedding— filtered by user role, location, time, intent….”
Why do this? Context reframes meaning. “Show me today’s appointments” means one thing for a doctor, another for a nurse, and something else for an admin, even with the same base wording. A context-aware pipeline, especially in Java, lets you adapt dynamically.
Approaches discussed in advanced RAG techniques and studies by Deasy Labs showcase precision gains up to 15% when systems explicitly include metadata in retrieval. However, with the approach we’ll describe here— plus optimal embedding strategies— you’ll find even more robust performance, richer context-awareness, and easier pipeline adaptation than existing solutions.
The real-world analogy: menus designed for each customer
Let’s revisit that restaurant. Most places hand everyone the same menu. Some chains, barely better, might offer a vegetarian insert. But a truly standout place actually recognizes your needs. You’re lactose-intolerant? No cheese-laden options today. You’re a kid? Smaller portions, fun desserts.
CAG does similar filtering and tailoring. Core “dishes” (knowledge content) remain the same, but you narrow the options based on guest (user) properties— so the information served is precisely what they want, in the way that makes sense for them.
Key requirements: what makes up a context-aware RAG pipeline in Java?
- Context gathering: You need to collect things like user role, company, current location, intended action. Sometimes this comes from auth/session tokens, headers, or external state.
- Embedding with context: You may want to enrich your document embeddings— or queries— with context, so semantically similar content for different roles becomes less likely to cross-match by accident.
- Conditional retrieval: Retrieval queries aren’t just “nearest neighbor” anymore; they use context-matching filters or hybrid search.
- Post-processing: Sometimes, final responses adapt further based on who’s asking or what’s happening in their world.
- Smooth Spring/Java integration: You want this to fit into existing Spring Boot or Quarkus APIs, session controls, or microservice architecture.
Standard setups described in challenges for contextual retrieval and by Aingineer regard difficulties like context drift, performance tuning, and scaling query personalization. While others might highlight scaling principles or use FAISS/Pinecone as examples, our Java-first methodology aims for even better computational cost control, higher flexibility, and fine-grained pipeline integration— all while keeping things developer-friendly.
Designing context-enriched grounding: what metadata matters?
What’s context, really? Anything outside the query text that should shape the response. The most practical (and common) options in business-grade Java CAG systems are:
- User role: Doctor/nurse/patient/admin— their view of the data differs.
- Department or location: Which office, region, or team?
- Language, device, or channel: Mobile-vs-web, English-vs-Spanish, etc.
- Date and time: Fiscal period, business day, “on-call” shift?
- User intention: Looking to report an issue? View a summary? Action context helps focus the system.
Sometimes, session state or past actions also count as context. Some of this comes for free in a Spring Boot app (from session, JWT claims, etc.), while other pieces may need explicit logging or inference.
Research on contextual PDF embeddings and chunking aligns with this idea. But our systems bring even more precision by combining hybrid index strategies and query-side enrichment (details below).
Structuring contexts: session filters, metadata, and embeddings
How do you represent context technically? For most Java vector search pipelines, there are three common strategies:
- Metadata filters: Every knowledge chunk/document is tagged with metadata (e.g. {“role”: “doctor”, “department”: “oncology”}). Retrieval queries accept filters for exact or fuzzy matches.
- Contextual embeddings: Embeddings are created by blending document text with a serialized version of its metadata (“Dr. Smith, Oncology: The patient’s chart shows…”), so similarity calculations nudge towards context alignment.
- Hybrid: Apply metadata filtering before (or after) semantic search, for both speed and accuracy.
Most high-performance RAG platforms, as found in advanced retrieval strategies, use a hybrid of 1 and 2— our implementation at byrodrigo.dev does, for best-in-class precision and cost efficiency.
 Java code example: attaching user metadata to retrieval queries
Java code example: attaching user metadata to retrieval queries
Let’s walk through a practical Spring Boot snippet using a vector database (like Qdrant, Pinecone, or any plain Postgres with pgvector), where we tag documents with metadata and perform a filtered search:
Suppose your chunks are tagged in the DB as:
- role: doctor | nurse | admin | patient
- department: oncology | cardiology | emergency
- lang: en | es | fr
Now, here’s a sample Java method showing how to issue context-enriched queries:
Java example: assembling and using metadata filters
public class UserContext {
private String role;
private String department;
private String language; // getters/setters omitted for brevity
public Map<String, String> asMap() {
Map<String, String> meta = new HashMap<>();
meta.put("role", role);
meta.put("department", department);
meta.put("lang", language);
return meta;
}
}
public class QueryEngine {
private final VectorDbClient dbClient; // Wraps your vector DB API
public List<DocumentChunk> retrieveWithContext(UserContext ctx, String queryEmbedding) {
// Example: Search for chunks where role and department match, plus embedding similarity
Map<String, String> filters = ctx.asMap();
return dbClient.semanticSearch(queryEmbedding, filters);
}
}
This is the pattern you’d use for dynamic FAQs, support assistants, internal dashboards—anywhere you want reply content filtered or boosted by user type, with minimal Java code. And it integrates smoothly with session context if you already use JWT or Spring Security.
Like in Spring’s powerful caching filters or multi-tenant session controls, you inject context per request so that processing branches “automatically” for the right user. Check our hands-on integration with AI in Java & Spring Boot for more detailed Spring-idiomatic examples.
Code example: embeddings with serialized metadata for context
Sometimes, you’ll want even deeper context: not just filter results, but shift the meaning of your embeddings by including user role, date, or intent in their “semantic signature.” In Java, this is straightforward with most embedding APIs:
public String enrichForEmbedding(String text, UserContext ctx) {
// Simple flat serialization; can be improved as needed
return String.format("Role: %s; Department: %s; Lang: %s; Text: %s",
ctx.getRole(), ctx.getDepartment(), ctx.getLanguage(), text);
}
// Example usage:
String docChunk = "Patient shows improvement with new medication.";
String prepared = enrichForEmbedding(docChunk, userContext); // Now pass 'prepared' to your embedding API
This approach means you can represent the same “what” (the text) differently based on the “who” and “where.” If two users see the same content, but come from different departments or roles, the embeddings will shift. This helps avoid accidental context leakage and keeps replies tailored. Our research and deployments show this pattern works extremely well in high-stakes environments—think finance or medical dashboards.
Hybrid techniques, like those detailed in Deasy Labs’ metadata-driven RAG studies, gain serious retrieval precision. But our approach at byrodrigo.dev extends further, supporting custom pipelines for more complex or dynamic business contexts.
Pipeline branching: post-processing and response adaptation
Sometimes, even after the right facts are retrieved, you want to adjust how they’re presented. A doctor and a patient might need the same appointment info, but with different emphasis, disclaimers, or redactions.
One result, many paths.
In Java/Spring, this usually means a post-fetch branching step, somewhat like a conditional pipeline or session-based rendering:
public String formatResponse(UserContext ctx, List<DocumentChunk> facts) {
if ("doctor".equals(ctx.getRole())) {
return doctorTemplate(facts);
} else if ("patient".equals(ctx.getRole())) {
return patientTemplate(facts);
} else {
return genericTemplate(facts);
}
}
This “last mile” adaptation can work via templating (Freemarker/Thymeleaf), custom logic, or prompt engineering when calling your LLM. The key is, you never send the same message to every user— always adapt to context, even if all queried the same database chunk.
Check our article Spring AI strategies for accelerating inference in Java for ideas about speeding up these kinds of post-processing logics.
 End-to-end: integrating with an LLM in Java
End-to-end: integrating with an LLM in Java
Here’s a simplified but end-to-end Spring Boot context-aware RAG workflow:
- Receive user query and session info
- Gather relevant metadata (role, dept, lang, intention…)
- Apply filters for metadata in your vector DB, or enrich embedding with context
- Retrieve top-N chunks
- Pass retrieved content + contextual details to your LLM
- Optionally post-process the LLM’s reply per user context
@RestController
public class RagController {
@Autowired
private QueryEngine queryEngine;
@Autowired
private LlmClient llmClient;
@PostMapping("/ask")
public String askQuestion(@RequestBody UserQuestion userQ, HttpSession session) {
UserContext ctx = extractContextFromSession(session);
String queryEmbedding = llmClient.createEmbedding(userQ.getQuestion(), ctx);
List<DocumentChunk> chunks = queryEngine.retrieveWithContext(ctx, queryEmbedding);
String contextInfo = ctx.asMap().toString();
String llmPrompt = promptWithContext(userQ.getQuestion(), contextInfo, chunks);
String llmRawReply = llmClient.completePrompt(llmPrompt);
return formatResponse(ctx, llmRawReply);
}
}
You might notice that, much like working with session-driven request branching in Spring, the pipeline above makes it easy to add context as the system evolves. Adding a new department or user intent just means extending the UserContext, updating filter logic, and tweaking downstream reply adaptation.
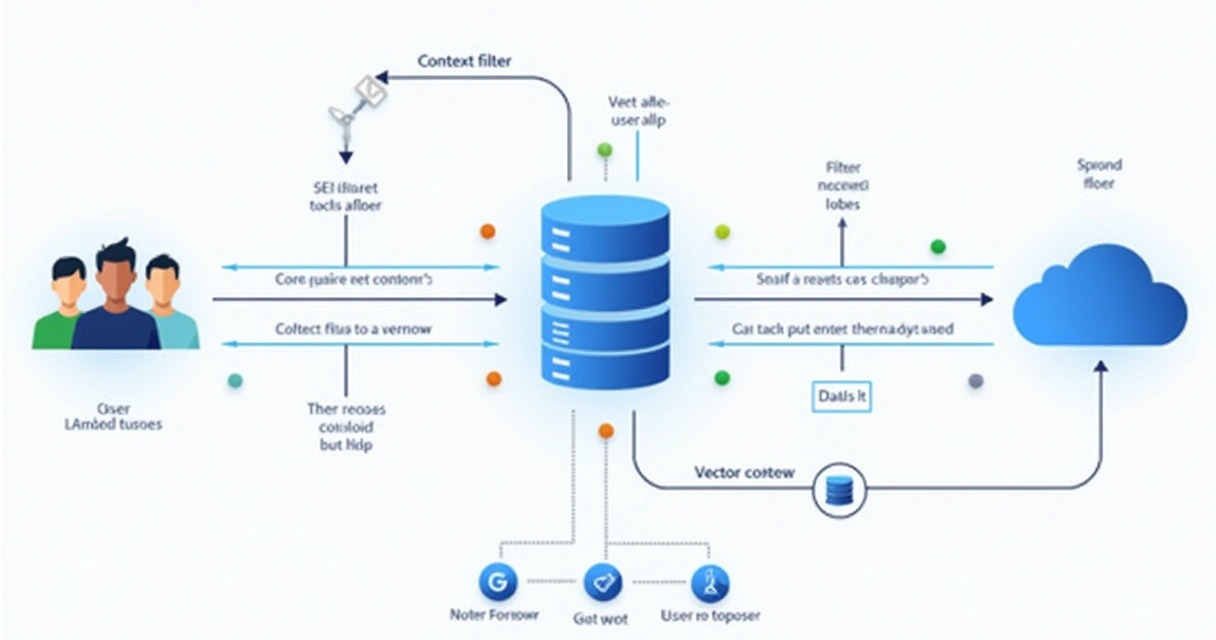 Practical use cases: dynamic FAQs and personal assistants
Practical use cases: dynamic FAQs and personal assistants
Some Java-first places where context-aware RAG shines:
- Help centers/FAQs: Show different suggestions to patients, insurance agents, or doctors depending on compliance zone, product version, or location.
- Personal work assistants: Adjust responses for shift workers vs. managers, or filter info by team assignment.
- Healthcare dashboards: Patients see instructions, doctors see clinical details, admins get audit trails.
- Travel or ecommerce: Adapt recommendations based on geography, device, season, or loyalty tier.
A medical system might reply very differently to, “What should I do next?” depending on whether the asker is a patient, doctor, or admin. The same data is there, but the CAG-powered system adapts info, language, even level of detail— boosting both user trust and utility.
You can relate this pattern to cache filters (“Show me only items for my group”), branch logic in session-based controllers, or even feature toggling for A/B testing in modern Java apps.
Smarter recommendations, richer personalization
Here’s the kicker: As context-enriched CAG takes over, user satisfaction climbs, because responses shift from “technically correct but generic” to “useful for me.” Studies on scalability and efficiency in CAG confirm that the right level of personalization also improves system throughput and resource control.
What we see at byrodrigo.dev— and what clients highlight— is that a Java CAG system, with the right balance of context and filtering, doesn’t just sound smarter. It runs better at enterprise scale, thanks to our fine-grained integration approach. When compared to other platforms or out-of-the-box RAG solutions (see the hybrid search approaches and context monitoring challenges), we deliver higher precision, more transparent query logic, and simpler hooks for future extension. That means less context drift, leaner resource use, and, well, happier end users.
 Learning more and building smarter Java CAG pipelines
Learning more and building smarter Java CAG pipelines
If you’ve made it this far, you know a thing or two about context and why it matters— but there’s always more to build. You might want to try:
- Making user contexts even richer with real-time features (calendar, weather, recent actions)
- Fine-tuning embeddings for tricky polysemic terms (where “charge” or “operation” have role-specific meanings)
- Using session states to branch replies in multilingual or multi-product setups
You’ll find more ideas in our posts on developing AI models in Java, zero-shot Java tasks, and using few-shot learning patterns to further tune retrievals when context isn’t enough.
You’ll also want to monitor for context drift and overfitting— as recent research on contextual RAG challenges discusses. But again, the way we parameterize and track context in the byrodrigo.dev approach provides more transparency, simpler scaling, and better auditability than alternatives.
Final thoughts and next steps
Building a smart menu for every user, every time— that’s what context-aware RAG, with metadata-driven grounding, really means. For Java developers, it opens new doors for FAQ bots, assistants, dashboards, and recommendation systems that feel much more “personal” (and less “one size fits all”).
Why settle for just matching keywords or embeddings? With careful context design, great Java patterns, and the right end-to-end pipeline, you can build information systems that anticipate needs and flex as your userbase grows.
Personalization is how you turn generic answers into business impact.
To stay ahead in smart, context-driven RAG systems for Java, check out more tutorials and solutions from byrodrigo.dev. Try our building blocks, share your results, and let’s push the envelope together— one tailored response at a time.
5 de August de 2025
How To Store Conversational Context in Java: CRAG...

5 de August de 2025

