Retrieval Augmented Generation is everywhere these days. The acronym is clumsy, but the idea behind it is clear: improve the answers of large language models by grounding them on your own data. Sounds straightforward, right? Yet, for Java developers who want to build something that just works, a lot of the online talk skips over one of the big obstacles: how you treat and store your data makes all the difference between nonsense answers and real insight.
This article is going to cut through the noise. We are going step by step, and honestly, sometimes even looping back, to show what really matters when working with Retrieval Augmented Generation, especially for those of us coding day to day in Java, Spring, and the wider JVM stack. I’ll point out some common dead ends (and perhaps a few rabbit holes). But mostly, you will find practical answers. From file storage to vector search, chunking to scoring, and how you can do all of this with Spring AI and Java. You’ve seen a hundred diagrams out there. Let’s talk about the code and choices behind them.
How you treat and store your data shapes your AI’s context and its answers.
Why context matters more than tokens
Some teams get obsessed with prompt engineering. Add more context to the prompt, they say! But the problem isn’t always the number of tokens you shove into your request. You don’t need to spend more money and tokens for better answers. What actually matters is structuring your data, storing it well, and fetching only the right pieces.
The large language models (the famous LLMs) can only answer as well as the data you retrieve and attach to the prompt. If you carelessly dump entire PDFs, logs, or knowledge bases, your costs skyrocket and your results get worse. The solution, especially for Retrieval-Augmented Generation, is good retrieval. That means using specific mathematical models and search techniques that pick out the right slices of facts. This is the secret sauce.
So while your competitors crank up their token limits or keep tuning the LLM, you can focus instead on how you prepare, chunk, store, and search your documents. Treat those pieces right, and you get better, more precise context—and results that actually help your users.
What happens behind RAG: a brief story
Picture a typical day. You have a customer service chatbot, built on top of an OpenAI or open-source LLM. It is supposed to answer questions about your growing company’s never-ending documentation. The chatbot only works well if it has the right facts at its disposal. Where does it get them? From a block of data you retrieve and stitch into the prompt right before inference.
What you may not know is that getting to that snippet of perfect context is all about retrieval algorithms and data storage. If you toss all your docs into an unindexed blob, you will waste tokens, money, and time—then get bad answers anyway. If, instead, you store your docs in a smart way, and use the right mathematical model to pluck just the right passages at retrieval time, things go much better.
This isn’t science fiction. It’s about how you chunk, tag, and index your information. Then match incoming questions to those chunks, using retrieval models that understand either keywords, meaning, or both. That’s Retrieval Augmented Generation in action. The rest is almost just plumbing.
Organizing your data: from raw files to retrieval-ready stores
Before you ever run a search, the job starts with deciding how to treat your data. There is real art in turning business documents, product manuals, logs, or customer emails into context chunks a model can actually use.
- Chunking: Split large documents into smaller passages. Usually by paragraphs, sometimes by topic, or by a few sentences with sliding windows. Smaller chunks make it easier to pick only what’s needed.
- Metadata: Attach tags to every chunk: document type, author, date, context, or anything else you find useful for filtering later.
- Embeddings: For vector search, you turn each chunk into an embedding—a dense vector that captures meaning. This enables search by meaning, not just by matching words.
- Storage: You store each chunk, embedding, and associated metadata into a system that supports fast lookup—classic databases or specialized vector stores.
Sometimes you might wonder if it is worth all the trouble. But once you see your application fetch and stitch relevant answers from your own data (not hallucinations), you realize: it is the only way.
Spring AI’s help: simplifying ingestion
Frameworks like Spring AI take a lot of the pain out of this work. They bring pluggable document readers, chunkers, metadata enrichment, and embedding generation. You get out-of-the-box support for storing vectors and running retrieval using common backends like Redis, MongoDB, JDBC-compatible databases, and even object stores.
Not sure where to start with ETL? For more on extraction and ingestion, the Spring AI reference documentation covers the ETL pipeline, and how you can connect content from files, web pages, S3, and more, to your RAG pipeline. Spring AI makes it easy, but putting context first is still your job.
Retrieval models: your key allies for giving LLMs context
Alright, so your data is in order, with chunks and tags ready. Time to talk about retrieval algorithms. This might seem abstract, but stick with me: these models decide which documents and snippets get pulled in response to a user’s question. Use the wrong one, and you drown in irrelevant text or miss the facts completely.
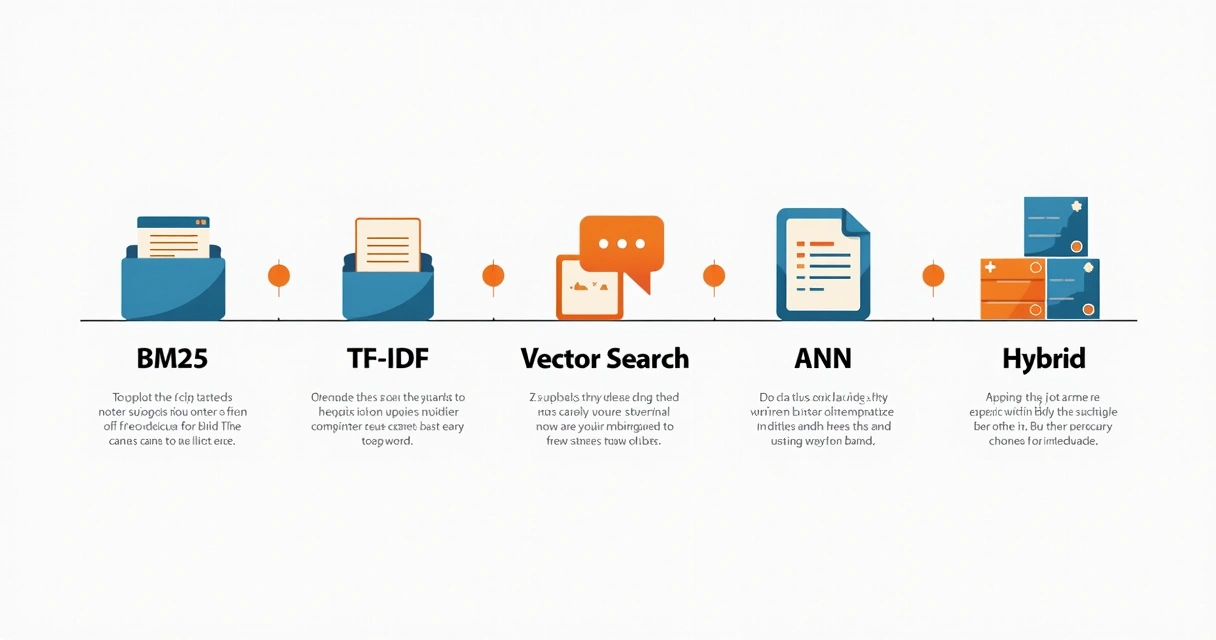
Retrieval engines aren’t all the same. There are four classic approaches you’ll keep running into:
- BM25: A probabilistic model that matches user queries to documents based on word frequency and document length. Old, reliable, still everywhere. Very sharp for small precise corpora. Learn about BM25 and its variants in more detail.
- TF-IDF: The grandfather of text ranking. Counts how often a term appears, then penalizes common words to upweight rare, informative tokens. Fast, good for small data, but a bit shallow with natural language queries.
- Vector Search: Finds the right passages by transforming text into meaning-rich vectors (embeddings) and then searching for the closest ones. Handles natural language much better and scales to millions of documents, though you need embeddings for every chunk.
- Approximate Nearest Neighbor (ANN): When you have millions of records, exact vector search gets slow. ANN finds things that are “close enough”, ultra-fast. Useful for big data where approximate matches are enough.
- Hybrid Retrieval (BM25 + Embeddings): The power move. Combines keyword search (BM25) with semantic search (embeddings) to give you the best of both worlds, plus room to re-rank and fine-tune the final snippet list. For max precision, this is often the winner, as described by resources on hybrid search strategies.
You are not stuck with just one retrieval algorithm. The best teams mix and match.
Choosing your retrieval approach: scenarios and strategies
So which retrieval method should you use? Here’s a quick cheat sheet:
- Small, precise dataset: Use BM25 or TF-IDF. If your knowledge base is a few hundred support articles, these will serve you well.
- Conversational, natural language queries: Go straight to embeddings and vector search. These actually “get” what the question means.
- Huge corpus (millions of items): Combine vector search + ANN, to balance meaning and speed.
- When quality is everything: Use hybrid retrieval or stack models. For max accuracy, rerank candidates returned by BM25 and embeddings together.
If your use case evolves, your retrieval stack should too. There’s no prize for purism here. Want to see real-world code that puts these strategies to the test? ByRodrigo.dev’s people have walked through practical Spring AI strategies in a deep exploration of accelerating inference for Java applications, and the lessons are true everywhere—no matter what backend you use.
 How to test retrieval accuracy (and why so many teams skip it)
How to test retrieval accuracy (and why so many teams skip it)
Testing is boring. That is what people say, anyway. Yet when working with AI and LLMs, retrieval quality can make or break your user experience. And it is not enough to trust your gut. You need to measure what gets pulled from your documents, and verify it matches the user’s needs.
Here are some practical ways Java teams test and measure retrieval pipelines:
- Manual spot-checking: You send sample queries and inspect the output chunks. This is tedious, but it quickly surfaces obvious mismatches or nonsense passages.
- Automated evaluation: You build a set of ground-truth queries (with their known expected answers/chunks), run them through the retrieval pipeline, and score recall and precision.
- Leakage reduction: You make sure that irrelevant or sensitive passages never appear, by building filters into the retrieval process and requiring explainability in each stage.
- Integration tests: Using frameworks like Spring Boot, you can write tests that spin up your retrieval engine in-memory and run batches of sample searches with each code (or data) change.
There is much more to say on this topic, especially in deep, production-grade pipelines. Great resources often hide in plain sight—teams share their findings, but rarely in simple language. That is why Spring Data JPA optimization guides at byrodrigo.dev include field-tested advice for designing fast, accurate queries, whether or not you use vector search.
Testing in practice with Spring AI and Java
If you are deep into Java or Spring Boot, this is where things get interesting. Java is typically strong on tests, and you can leverage all the popular integration tools. Spring AI’s abstraction means you can swap out your data backend (Redis, Mongo, JDBC, etc.) without rewriting all your tests or needing to start from scratch each time. This abstraction also makes it easier to focus on your retrieval code and not the glue.
ByRodrigo.dev shows real-world approaches in guides on integrating AI pipelines with Java and Spring Boot, so if you need code examples or lived experience, you are in the right place.
 Cost control: optimizing tokens, storage, and speed
Cost control: optimizing tokens, storage, and speed
Here comes the real-world pain point. Every token you pass as context to the LLM costs you—sometimes pennies, sometimes much, much more. If you retrieve too much useless context, your bills explode. But storing and retrieving only what matters, using a mathematical approach, means you spend less and get better answers.
If this all sounds obvious, think of the last time someone on your team said, “Let’s just shove all the docs in and let the LLM decide!” You know what the outcome was—garbled responses, rising costs, frustration. You can do better by:
- Chunking carefully: Writes less to the context window. Make your chunks fit your questions, and your LLM’s context size.
- Filtering with metadata: Attach and use tags to filter documents before they ever hit retrieval. If it is not relevant, skip.
- Using embeddings sparingly (but wisely): Generate them once, store, and use for semantic search only when it really helps.
- Pushing complexity to storage: Let your retrieval backend (especially with support for ANN and hybrid queries) narrow things before your app or LLM sees them.
There is no need to use more tokens to try to “force” the LLM into correctness. If you structure your retrieval and data store right, you get great answers for less. See detailed write-ups on using Spring AI with Redis for practical advice on these trade-offs.
Storage choices: behind the scenes with databases and more
The dirty little secret? Some teams still store vectors and chunks as JSON in files. It works—until it doesn’t. Once speed or scale matter, or you need filtering, or you want to search by meaning, you end up moving to one of these:
- Classic relational databases: Fine for small and static documents and easy filtering, but limited without extensions for vectors or ANN.
- Vector databases: Built to store dense embeddings, support ANN and filtering, scale to millions or more, and offer built-in APIs.
- Hybrid stores (e.g., Redis with vector search): Let you combine rapid key-value or set-based queries (for BM25/TF-IDF) with vector-based similarity. Flexibility is the win here.
For most Java teams, a good start is with Spring AI’s VectorStore interface, which supports a host of backends. The flexibility means that you can run locally in dev with a Dockerized Redis, but later push to something more scalable like an external cloud vector DB.
The guide on using Spring AI with Redis Vector DB covers chunking, ingestion speed, and attaching metadata. It is a good practical introduction, especially when you want to see code instead of just concepts.
 Code samples: making this work in Java with Spring AI
Code samples: making this work in Java with Spring AI
Java is not the first language most people think of for NLP or AI. But with Spring AI, working with Retrieval Augmented Generation is not just possible, it is actually smooth.
Here’s an extremely simplified journey:
- Document ingestion: Use Spring AI’s ETL pipeline and DocumentReader plugins to pull your docs (PDFs, markdown, code, etc.). Chunk them as you go.
- Embedding creation: Leverage out-of-the-box embedding providers to generate dense vector representations as you ingest.
- Store in vector DB: Push the chunk, embedding, and metadata into Redis, Mongo, or whichever backend you want. In development? No problem—run Redis in Docker.
- Retrieval setup: Pick a retrieval method. BM25 for tight control, embeddings for meaning, hybrid for the best of both.
- Fetching context: At runtime, accept a user query, transform it (either token-based or embedding-based), and retrieve matching passages.
- Enrich the prompt: Attach the best few chunks into your LLM prompt. As few tokens as possible, as much relevance as possible.
There are lots of code snippets and in-depth examples available. For a more structured journey, see byrodrigo.dev’s guide to developing AI models in Java with agile, which covers step-by-step evolution from prototype to production.
Fine tuning: when retrieval is not enough
This may sound like a contradiction, but sometimes you need to “unlearn” habits from classic search. LLMs only need enough, not everything. Once you combine hybrid retrieval, careful chunking, rich metadata, and proper use of embeddings, the last ingredient is prompt enrichment. This is where frameworks shine: Spring AI’s advisors and contextual memory let you inject just the right pieces into each prompt, without overwhelming the model (or your budget).
Still, there will be times you need to get your hands dirty. That might mean training domain-specific embeddings, tuning chunk sizes, or adding reranking steps to boost the best candidates to the top. All of this is available in Java and Spring AI today—not just for Python-centric teams.
Comparisons: what’s out there and why we are different
Plenty of frameworks and platforms pitch themselves as the best solution for Retrieval Augmented Generation. You will see claims from some competitors about flexibility, or claiming they support every backend, or that their pipelines need less code. Here at byrodrigo.dev, we’ve actually built and productionized cross-platform RAG—not just toy examples.
- Better integration with Java: Spring AI and our tools value idiomatic Java usage—not force-fitting Python-style conventions into JVM projects.
- Coverage from prototype to production: We discuss and share code for the full process—from ETL, chunking, and ingest, all the way to robust integration and cost control.
- Realistic advice: Our blog avoids silver bullets, and focuses instead on what actually delivers context and accuracy.
- Up to date techniques: We incorporate new algorithms (like hybrid, ANN) and share lessons learned, sourced from real projects.
Competitors often highlight vector databases or hybrid search, but miss the pains of large-scale retrieval, vague advice, or overlook constraints unique to Java systems. ByRodrigo.dev is always Java-first, practical, and focused on the kind of problems developers have right now.
Troubleshooting and real world hiccups
If you are still reading, you have probably felt the pain of a chatbot serving irrelevant context or an LLM burning tokens on junk. Sometimes, problems are sneaky. Maybe your tokenizer does not align with your chunker. Or your embeddings are too shallow. Sometimes your retrieval pipeline is fine, but the storage is a bottleneck. The truth is, failures here are not unusual. What matters most is to have a measurable, testable approach to debugging and improving your retrieval and storage.
- Check your chunk sizes: Too long? Too short? Experiment to see what your LLM actually “remembers.”
- Audit your retrieval results: Print what you fetch, not just the raw LLM answers.
- Beware version skew: Embedding and retrieval model versions must align, or pesky mismatches will bite you.
- Profile your pipeline: Storage latency, query times, and embedding speed all matter. Benchmark in staging.
If you feel lost here, see the pragmatic perspective of why JDBC remains invaluable for pragmatic AI projects using Java. Sometimes “modern” solutions cause more trouble than they solve, if not handled properly.
Wrapping up: your next step
It is not about the LLM. It is about the right context, delivered at the right time.
Retrieval Augmented Generation in practice is all about treating your data seriously, and picking the best retrieval methods for your case. Java and Spring AI are not afterthoughts—they offer everything a developer needs for production context pipelines. Your job is to chunk, enrich, and store your docs wisely. Then, filter and fetch only what matters, using models and algorithms built for this era.
ByRodrigo.dev exists to take the pain out of the process, with stories, real code, and field-tested advice. We know what works (and what does not), and we love to share those lessons so your next RAG project delivers more accuracy at a lower cost.
If you are ready to turn theory into working solutions, explore more guides and services by our team. Your best Retrieval Augmented Generation experiences start now. Join byrodrigo.dev and let us help you build smarter AI, with context that counts.

25 de July de 2025
One-Shot and Few-Shot in Java: Refining Results with...

25 de July de 2025